本文旨在深入解析 Python 内置 logging 模块的核心设计理念,特别是 Logger 的层级结构、属性继承机制,以及如何实现对日志的精准控制。
在你阅读完本文后,能对Python内置logging模块如何使用有一个清晰的理解,如果文中出现错误,请您留下建议,谢谢。
名词速查:核心术语一览
| 术语 | 一句话解释 |
|---|
| Logger | 你在代码里调用的对象,负责"发出"日志记录 |
| Handler | 决定日志"输出到哪里"(控制台 / 文件 / 网络等) |
| Formatter | 决定日志"长什么样"(时间、级别、内容等格式) |
| Filter | 可选,决定某条日志记录"要不要被处理" |
四者关系:Logger 产生记录 → Handler 决定去处 → Formatter 决定格式 → Filter 可在任意层拦截。
担忧的体现与解决思路
在开发本地项目并准备将其作为第三方库发布时,开发者最担忧的问题是:我的日志配置会不会影响到使用我库的其他项目?
- 担忧:强制输出日志,污染宿主项目的控制台或文件。
- 解决:作为库(Library),绝对不要在模块级别调用 logging.basicConfig() 或添加 StreamHandler/FileHandler。
- 在示例中的体现:在 inspect.py 中,setup_logging()(配置 Handler 和 Formatter 的操作)被严格限制在 if __name__ == "__main__": 块内。这意味着,如果其他项目 import logging_inspect,这些配置代码不会执行,从而保证了“零侵入”。
- 担忧:宿主项目无法区分或控制我库里的日志。
- 解决:库内部的所有日志记录器必须使用统一的命名空间(通常是包名)。
- 在示例中的体现:所有子模块都使用 logger = logging.getLogger(__name__)。这样,宿主项目只需通过 logging.getLogger("logging_inspect").setLevel(logging.WARNING),就能一键控制你整个库的日志级别,而不会影响宿主项目自身的日志。
- 最佳实践:添加 NullHandler
核心概念:Logger 树形层级结构
Python 的 logging 模块采用了一种基于点号分隔命名的树形层级结构来管理 Logger。
树的根节点:Root Logger
在 Python 的日志系统中,存在一个特殊的、默认的 Logger,它的名字是 root。
- 全局控制:它是所有其他 Logger 的最终祖先。如果你没有为子 Logger 设置级别(即 NOTSET),它们最终会继承 Root Logger 的级别(默认是 WARNING)。
- 获取方式:
- logging.getLogger()(不传参数)返回的就是 Root Logger。
- logging.root 也可以直接访问它。
- 快捷方法:你平时直接调用的 logging.info("msg")、logging.warning("msg"),实际上就是在调用 Root Logger 的方法。
- 全局配置:logging.basicConfig() 默认就是为 Root Logger 配置 Handler 和 Formatter。
__name__ 的妙用
在 Python 模块中,推荐使用以下方式获取 Logger:
TEXT
- 原理:__name__ 是当前模块的完整路径(例如 logging_inspect.level1.level2.log_inspect_level2)。
- 优势:这会自动构建一个与你的项目包/模块结构完全一致的 Logger 树。
层级关系图解
正在渲染 Mermaid 图表...
每个节点名称就是对应模块中 __name__ 的实际值,也是调用 logging.getLogger(__name__) 时所用的 key。
- logging_inspect.level1.level2 是 logging_inspect.level1.level2.log_inspect_level2 的父级。
- 这种层级关系是实现日志继承和统一控制的基础。
属性继承与控制机制
理解 Logger 的属性如何在层级间传递,是实现精准控制的关键。
disabled 属性:不继承
- 作用:直接禁用某个具体的 Logger,使其不再处理任何日志记录。
- 特性:不继承。禁用父级 Logger,不会影响子级 Logger 的正常工作。
- 源码位置参考:logging.Logger.handle 方法中会检查 self.disabled。
- 应用场景:当你只想关闭某一个特定文件(模块)的日志时。
PYTHON
level 属性(日志级别):继承
- 作用:决定 Logger 处理哪种严重程度及以上的日志(DEBUG < INFO < WARNING < ERROR < CRITICAL)。
- 特性:继承。如果一个 Logger 的级别是 NOTSET(默认值 0),它会沿着树形结构向上查找,直到找到一个显式设置了级别的祖先 Logger,并使用该级别。
- 源码位置参考:logging.Logger.getEffectiveLevel 方法实现了向上查找逻辑。
- 应用场景:当你希望统一控制某个包及其所有子模块的日志级别时。
PYTHON
propagate 属性与 Handler:向上传递
- 作用:决定子 Logger 产生的日志记录是否要传递给父级 Logger 的 Handler 进行输出。
- 特性:默认值为 True。这意味着子模块的日志不仅会被自己的 Handler 处理(如果有),还会一直向上传递,被父级、祖父级的 Handler 处理。
- 源码位置参考:logging.Logger.callHandlers 方法中通过 c.propagate 控制循环。
- 应用场景:当你希望某个子模块的日志输出到独立文件,且不再输出到主控制台时。
PYTHON
propagate 日志传递流向图(propagate=True 时的完整链路):
正在渲染 Mermaid 图表...
若将 level2_logger.propagate = False,则 level2 → level1 的箭头断开,日志只写入文件,不再出现在控制台。
源码级原理解析 (基于 CPython 3.12)
getLogger 的单例模式
logging.getLogger(name) 实际上是从一个全局的 Manager 对象中获取 Logger。如果该名称的 Logger 不存在,则创建并缓存;如果存在,则直接返回。这保证了在不同文件中使用相同名称获取到的是同一个 Logger 实例。
(参考源码:logging.__init__.py 中的 Manager.getLogger)
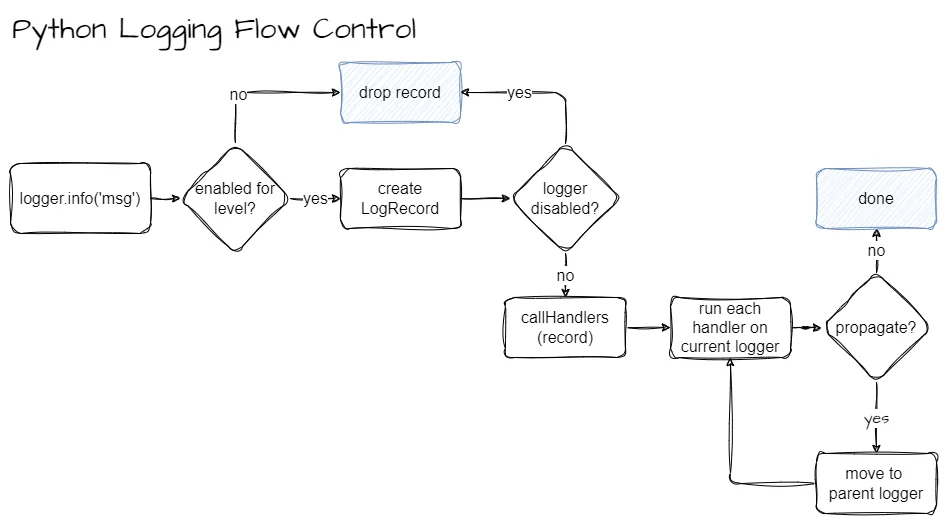
日志处理流程 (Logger.handle)
当调用 logger.info("msg") 时,核心流程如下:
- 级别检查:调用 isEnabledFor(level),内部调用 getEffectiveLevel() 向上查找有效级别。如果当前日志级别低于有效级别,直接丢弃。
- 创建 LogRecord:将日志信息封装为 LogRecord 对象。
- 处理记录:调用 handle(record)。
- 检查 self.disabled,如果为 True,直接返回。
- 调用 callHandlers(record)。
- 调用 Handlers (callHandlers):
- 遍历当前 Logger 的所有 Handler,调用它们的 handle 方法。
- 检查 self.propagate。如果为 True,则将当前 Logger 切换为其父级 Logger,重复上述 Handler 调用过程,直到遇到 propagate=False 或到达 Root Logger。
(参考源码:logging.__init__.py 中的 Logger.handle 和 Logger.callHandlers)
应用实践落地:具体实现步骤
了解了上述原理后,在实际项目中(无论是开发应用还是库),我们应该如何落地?以下是一个标准的实践步骤:
步骤 1:在所有模块中统一获取 Logger
在你的每一个 .py 文件(如 module_a.py, module_b.py)的顶部,都使用以下标准写法:
PYTHON
步骤 2:区分“库”与“应用”的配置策略
如果你在开发一个库(Library,供他人 import):
- 绝对不要在模块级别调用 logging.basicConfig() 或添加任何 StreamHandler/FileHandler。
- 在你库的顶层 __init__.py 中,添加一个 NullHandler,这也是官方文档建议,防止在宿主未配置日志时报错:
如果你在开发一个应用(Application,直接运行的程序):
- 创建一个专门的日志配置模块(如 logger.py)或在入口文件(如 main.py)的 if __name__ == "__main__": 块中进行集中配置。
- 配置 Formatter(日志格式)和 Handler(输出目标,如控制台、文件)。
步骤 3:在应用入口集中配置(以应用为例)
PYTHON
步骤 4:根据需求进行精准控制(在应用入口或配置模块中)
在 setup_logging 之后,你可以利用层级特性进行微调:
PYTHON
通过以上 4 个步骤,你就能在项目中建立起一个清晰、可控且不具侵入性的日志系统。